I read a blog post by Alex Muscar, “Beautiful Binary Search in D“. It describes a binary search called “Shar’s algorithm”. I’d never heard of it and it’s impossible to google, but looking at the algorithm I couldn’t help but think “this is branchless.” And who knew that there could be a branchless binary search? So I did the work to translate it into a algorithm for C++ iterators, no longer requiring one-based indexing or fixed-size arrays.
In GCC it is more than twice as fast as std::lower_bound, which is already a very high quality binary search. The search loop is simple and the generated assembly is beautiful. I’m astonished that this exists and nobody seems to be using it…
Lets start with the code:
template<typename It, typename T, typename Cmp>
It branchless_lower_bound(It begin, It end, const T & value, Cmp && compare)
{
size_t length = end - begin;
if (length == 0)
return end;
size_t step = bit_floor(length);
if (step != length && compare(begin[step], value))
{
length -= step + 1;
if (length == 0)
return end;
step = bit_ceil(length);
begin = end - step;
}
for (step /= 2; step != 0; step /= 2)
{
if (compare(begin[step], value))
begin += step;
}
return begin + compare(*begin, value);
}
template<typename It, typename T>
It branchless_lower_bound(It begin, It end, const T & value)
{
return branchless_lower_bound(begin, end, value, std::less<>{});
}
I said the search loop is simple, but unfortunately the setup in lines 4 to 15 is not. Lets skip it for now. Most of the work happens in the loop in lines 16 to 20.
Branchless
The loop may not look branchless because I clearly have a loop conditional and an if-statement in the loop body. Let me defend both of these:
- The if-statement will be compiled to a CMOV (conditional move) instruction, meaning there is no branch. At least GCC does this. I could not get Clang to make this one branchless, no matter how clever I tried to be. So I decided to not be clever, since that works for GCC. I wish C++ just allowed me to use CMOV directly…
- The loop condition is a branch, but it only depends on the length of the array. So it can be predicted very well and we don’t have to worry about it. The linked blog post fully unrolls the loop, which makes this branch go away, but in my benchmarks unrolling was actually slower because the function body became too big to be inlined. So I kept it as is.
Algorithm
So now that I’ve explained that the title refers to the fact that one branch is gone and the other is nearly free and could be removed if we wanted to, how does this actually work?
The important variable is the “step” variable, line 7. We’re going to jump in powers of two. If the array is 64 elements long, it will have the values 64, 32, 16, 8, 4, 2, 1. It gets initialized to the nearest smaller power-of-two of the input length. So if the input is 22 elements long, this will be 16. My compiler doesn’t have the new std::bit_floor function, so I wrote my own to round down to the nearest power of two. This should just be replaced with a call to std::bit_floor once C++20 is more widely supported.
We’re always going to do steps that are power-of-two sized, but that’s going to be a problem if the input length is not a power of two. So in lines 8 to 15 we check if the middle is less than the search value. If it is, we’re going to search the last elements. Or to make it concrete: If the input is length 22, and that boolean is false, we’ll search the first 16 elements, from index 0 to 15. If that conditional is true, we’ll search the last 8 elements, from index 14 to 21.
input 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
line 8 compare 16
when false 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
when true 14 15 16 17 18 19 20 21Yes, that means that indices 14, 15 and 16 get included in the second half even though we already ruled them out with the comparison in line 8, but that’s the price we pay for having a nice loop. We have to round up to a power of two.
Performance
How does it perform? It’s incredibly fast in GCC:

Somewhere around 16k elements in the array, it’s actually 3x as fast as std::lower_bound. Later, cache effects start to dominate so the reduced branch misses matter less.
Those spikes for std::lower_bound are on powers of two, where it is somehow much slower. I looked into it a little bit but can’t come up with an easy explanation. The Clang version has the same spikes even though it compiles to very different assembly.
In fact in Clang branchless_lower_bound is slower than std::lower_bound because I couldn’t get it to actually be branchless:

The funny thing is that Clang compiles std::lower_bound to be branchless. So std::lower_bound is faster in Clang than in GCC, and my branchless_lower_bound is not branchless. Not only did the red line move up, the blue line also moved down.
But that means if we compare the Clang version of std::lower_bound against the GCC version of branchless_lower_bound, we can compare two branchless algorithms. Lets do that:

The branchless version of branchless_lower_bound is faster than the branchless version of std::lower_bound. On the left half of the graph, where the arrays are smaller, it’s 1.5x as fast on average. Why? Mainly because the inner loop is so tight. Here is the assembly for the two:
| inner loop of std::lower_bound | inner loop of branchless_lower_bound |
|---|---|
| loop: mov %rcx,%rsi | loop: lea (%rdx,%rax,4),%rcx |
| mov %rbx,%rdx | cmp (%rcx),%esi |
| shr %rdx | cmovg %rcx,%rdx |
| mov %rdx,%rdi | shr %rax |
| not %rdi | jne loop |
| add %rbx,%rdi | |
| cmp %eax,(%rcx,%rdx,4) | |
| lea 0x4(%rcx,%rdx,4),%rcx | |
| cmovge %rsi,%rcx | |
| cmovge %rdx,%rdi | |
| mov %rdi,%rbx | |
| test %rdi,%rdi | |
| jg loop |
These are all pretty cheap operations with only a little bit of instruction-level-parallelism, (each loop iteration depends on the previous, so instructions-per-clock are low for both of these) so we can estimate their cost just by counting them. 13 vs 5 is a big decrease. Specifically two differences matter:
- branchless_lower_bound only has to keep track of one pointer instead of two pointers
- std::lower_bound has to recompute the size after each iteration. In branchless_lower_bound the size of the next iteration does not depend on the previous iteration
So this is great, except that the comparison function is provided by the user and, if it is much bigger, it can take many more cycles than we do. In that case branchless_lower_bound will be slower than std::lower_bound. Here is binary searching of strings, which gets more expensive once the container gets large:

More Comparisons
Why is it slower for strings? Because this does more comparisons than std::lower_bound. Splitting into powers of two is actually not ideal. For example if the input is the array [0, 1, 2, 3, 4] and we’re looking for the middle, element 2, this behaves pretty badly:
| std::lower_bound | branchless_lower_bound |
|---|---|
| compare at index 2, not less | compare at index 4, not less |
| compare at index 1, less | compare at index 2, not less |
| done, found at index 2 | compare at index 1, less |
| compare at index 1, less | |
| done, found at index 2 |
So we’re doing four comparisons here where std::lower_bound only needs two. I picked an example where it’s particularly clumsy, starting far from the middle and comparing the same index twice. It seems like you should be able to clean this up, but when I tried I always ended up making it slower.
But it won’t be too much worse than an ideal binary search. For an array that’s less than 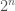
– an ideal binary search will use 
– branchless_lower_bound will use 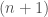
Overall it’s worth it: We’re doing more iterations, but we’re doing those extra iterations so much more quickly that it comes out significantly faster in the end. You just need to keep in mind that if your comparison function is expensive, std::lower_bound might be a better choice.
Tracking Down the Source
I said at the beginning that “Shar’s algorithm” is impossible to google. Alex Muscar said he read it in a book written in 1982 by John L Bentley. Luckily that book is available to borrow online from the Internet Archive. Bentley provides the source code and says that it’s got the idea from Knuth’s “Sorting and Searching”. Knuth did not provide source code. He only sketched out the idea in his book, and says that it came from Leonard E Shar in 1971. I don’t know where Shar wrote up the idea. Maybe he just told it to Knuth.
This is the second time that I came across an algorithm in Knuth’s books that is brilliant and should be used more widely but somehow was forgotten. Maybe I should actually read the book… It’s just really hard to see which ideas are good and which ones aren’t. For example immediately after sketching out Shar’s algorithm, Knuth spends far more time going over a binary search based on the Fibonacci sequence. It’s faster if you can’t quickly divide integers by 2, and instead only have addition and subtraction. So it’s probably useless, but who knows? When reading Knuth’s book, you have to assume that most algorithms are useless, and that the good things have been highlighted by someone already. Luckily for people like me, there seem to still be a few hidden gems.
Code
The code for this is available here. It’s released under the boost license.
Also I’m trying out a donation button. If open source work like this is valuable for you, consider paying for it. The recommended donation is $20 (or your local cost for an item on a restaurant menu) for individuals, or $1000 for organizations. (or your local cost of hiring a contractor for a day) But any amount is appreciated:
Make a one-time donation
Thanks! I have no idea how much this is worth to people. Feedback appreciated.
Donate